
Research
Computational Science

Stereo Vision Pipeline for Rigid-Body Pose Estimation
Developed a stereo reconstruction pipeline for real-time tracking of multiple rigid bodies with known geometry. The pipeline processes synchronized stereo image pairs through blob detection, followed by stereo correspondence matching with epipolar constraints to identify valid left-right marker pairs. A tree-based spatial clustering algorithm groups 3D reconstructed points and matches them to expected rigid-body geometries. A marker-locking mechanism handles partial occlusions and estimates pose with as few as three visible fiducials.
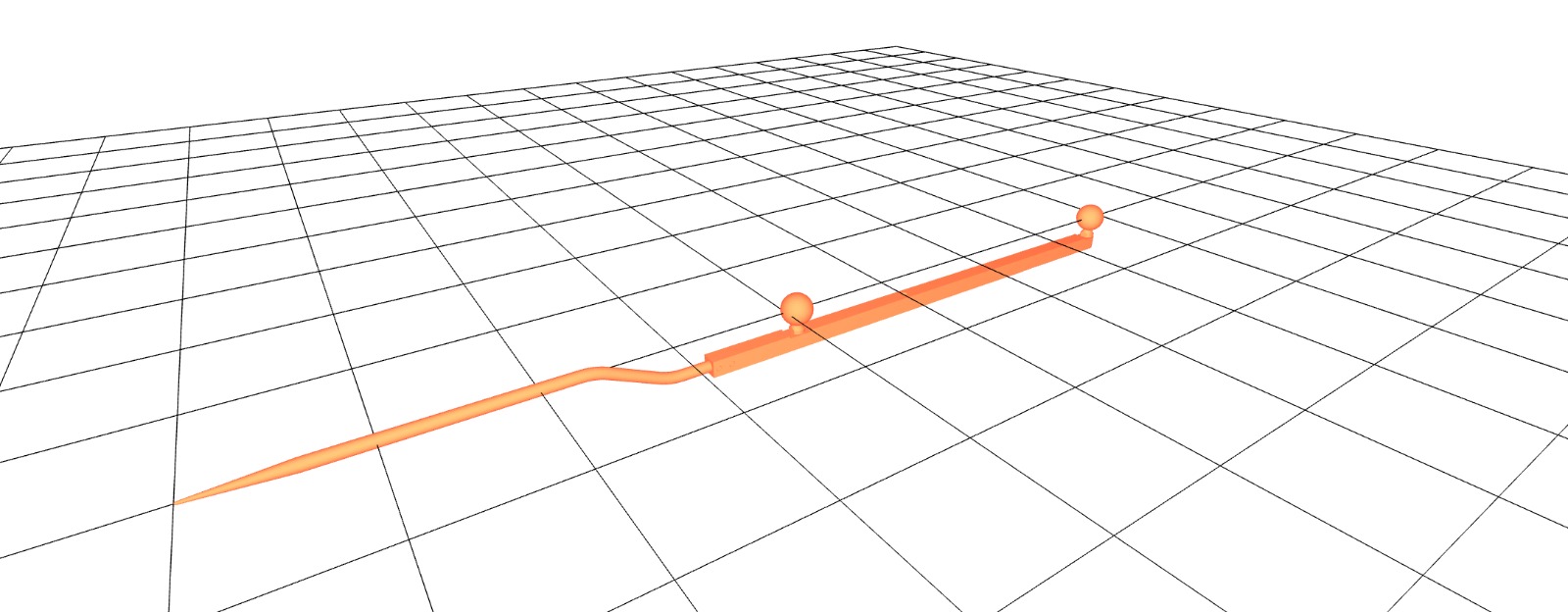
5DOF Pose Estimation for Collinear Fiducial Configurations
Implemented pose estimation for tools with collinear marker arrangements. The rotational symmetry around the tool axis creates ambiguity-spherical markers appear identical under axial rotation-reducing the observable degrees of freedom from 6DOF to 5DOF. The approach uses quaternions to align the detected marker direction with the tool's geometric axis. Direction vectors are preserved across frames to maintain orientation consistency and resolve point ordering.
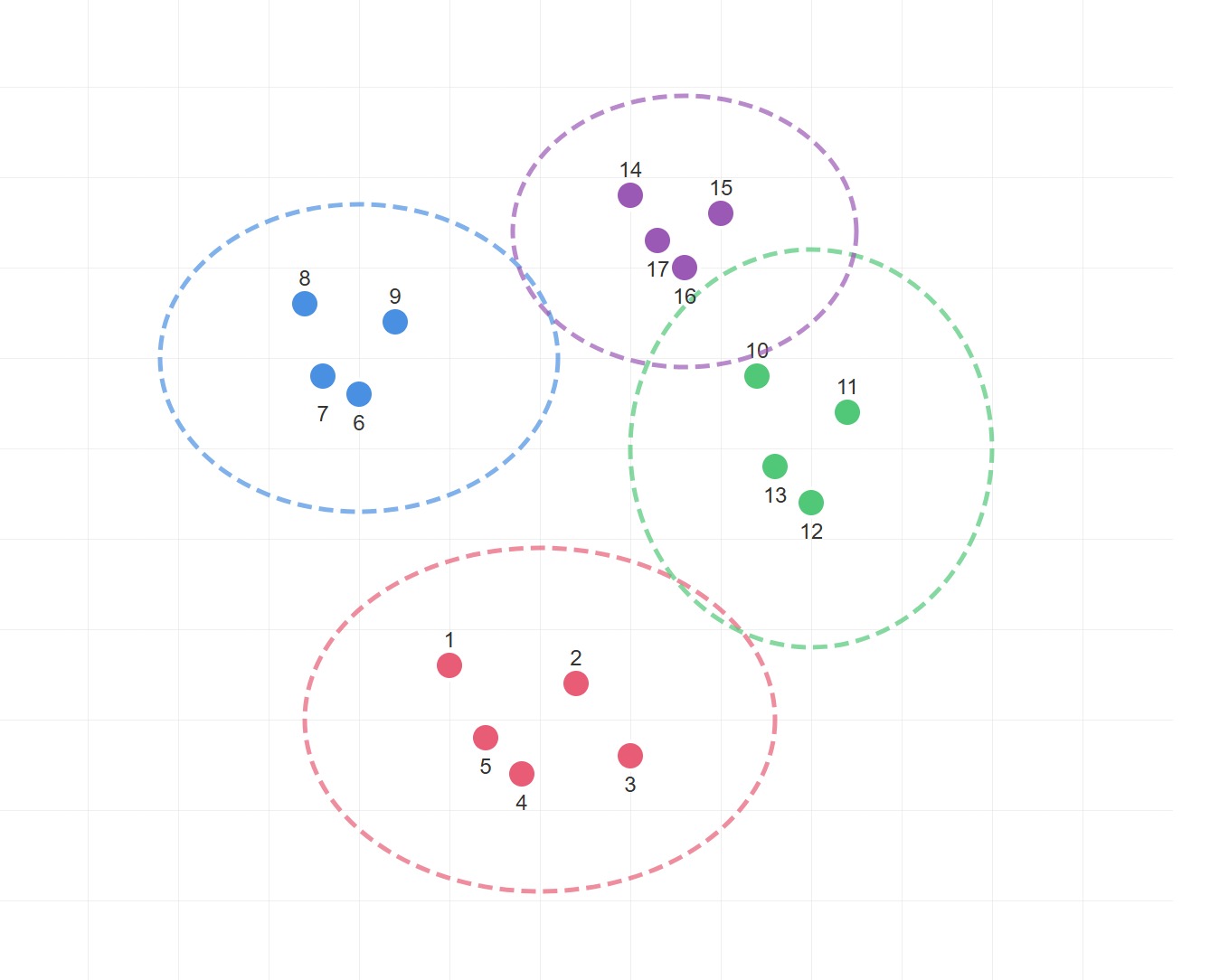
Spectral Methods for Rigid Body Identification and Correspondence
Worked on spectral clustering to group marker detections into distinct tools based on structural similarity. Traditional distance-based clustering fails when tools are spatially close or when geometric configurations violate simple proximity assumptions. The method constructs affinity matrices encoding pairwise relationships, applies eigendecomposition for soft cluster assignments, and implements eigenvector sign correction to maintain consistent correspondences.

Sub-Pixel Marker Localization via Geometric Refinement
Standard blob detection methods provide only pixel-level accuracy for marker centers, introducing systematic errors in pose estimation. Sub-pixel refinement samples image gradients along circular paths around detected markers and formulates a weighted least squares problem from gradient orientation constraints. The true center of curvature is found through eigendecomposition of the resulting system. Ellipse fitting handles perspective distortion where circular markers appear elliptical under viewing angles.
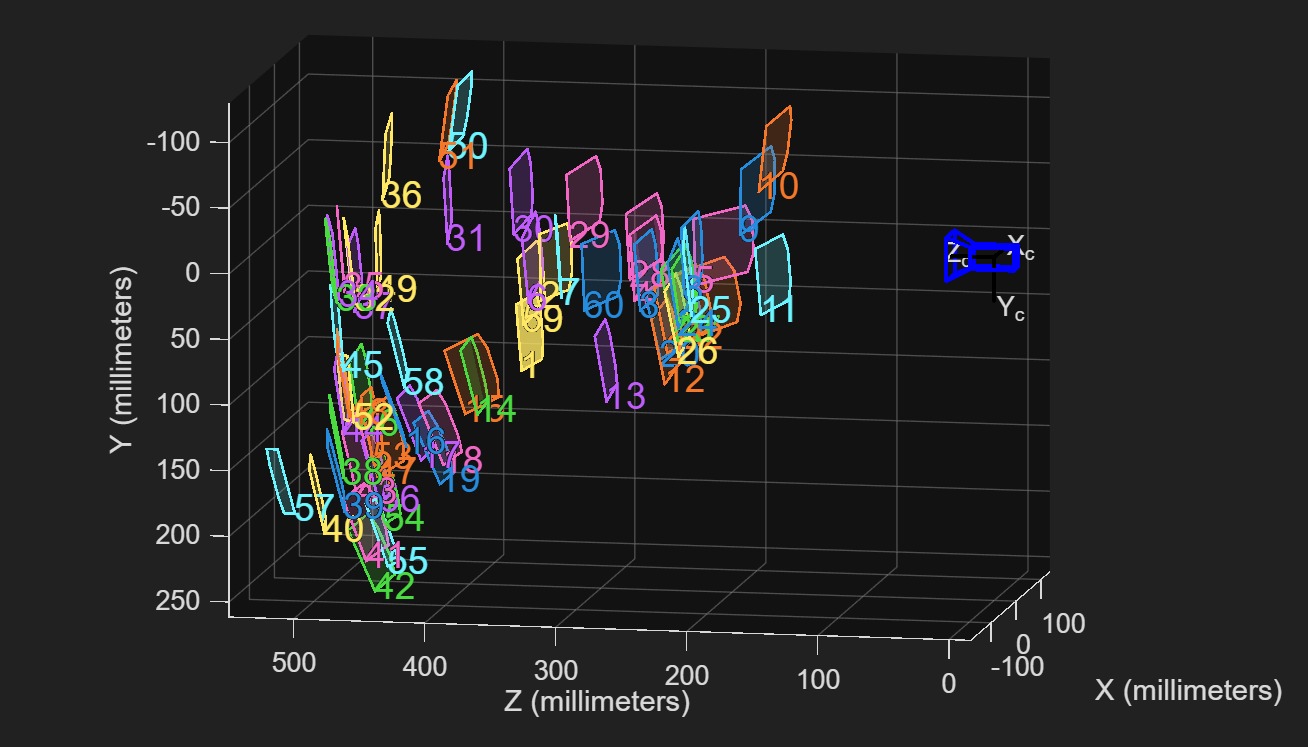
Optimization of Camera Calibration Parameters using Levenberg-Marquardt Non-Linear Least Squares
Implemented non-linear least squares to optimize the cameras parameters for both monocular and stereo camera calibration. Derived the equations to minimize the reprojection error, incorporating intrinsic parameters, radial and tangential distortion coefficients, and extrinsic poses. For stereo systems, enforced rigid transformation constraints between camera pairs while optimizing all parameters across multiple calibration views.
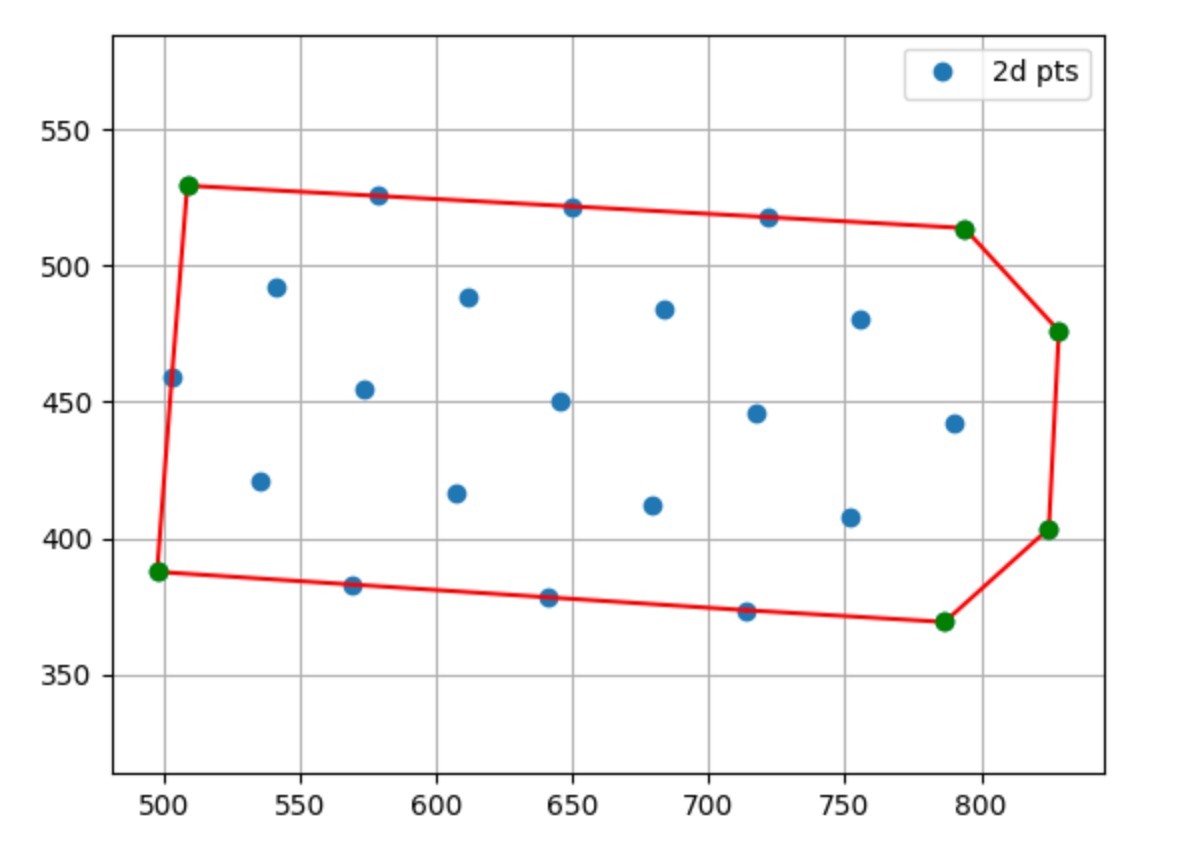
2D-3D Point Correspondence for Camera Calibration
Camera calibration requires matching 3D world points to their 2D image projections across frames with varying orientations. Worked on an algorithm using convex hull detection to identify board corners, longest parallel edge detection for orientation, and cross-product operations to fix a consistent origin. A homography computed from reordered corners maps all 3D points to the image plane, enabling automatic correspondence across arbitrary board orientations.
Biomedical Data Science
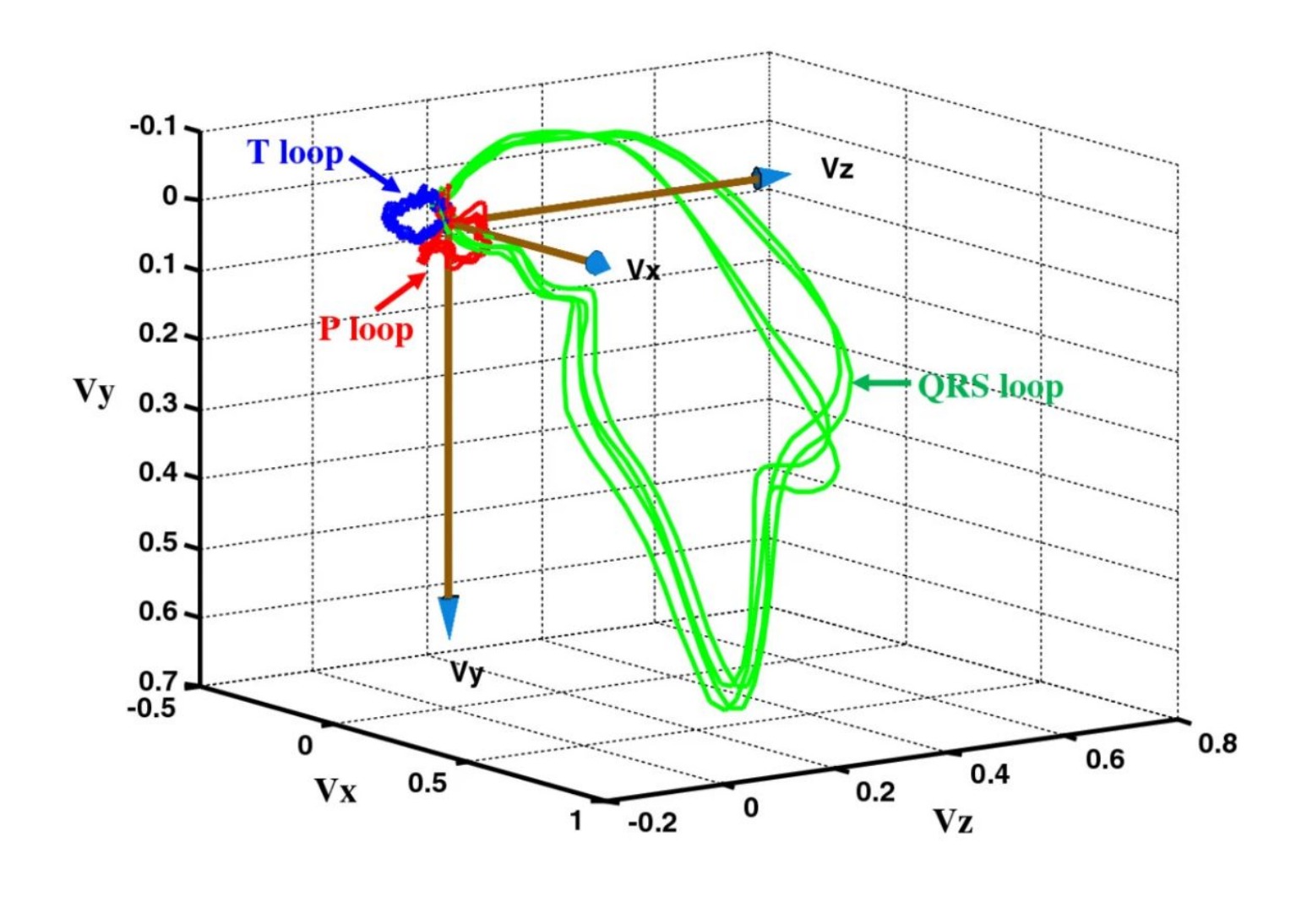
Generative AI Methods for Synthesizing Realistic ECG Data using Vectorcardiography | 2024
Developed a generative AI framework to synthesize realistic 12-lead ECG data for anomalous cardiac cases. Implemented Dower's transform to convert raw ECG signals into vectorcardiographic (VCG) X, Y, Z components, serving as spatiotemporal features for GANs and VAEs. Trained on PTB-XL dataset across five diagnostic classes, demonstrating improved downstream classifier performance when augmented with generated data.
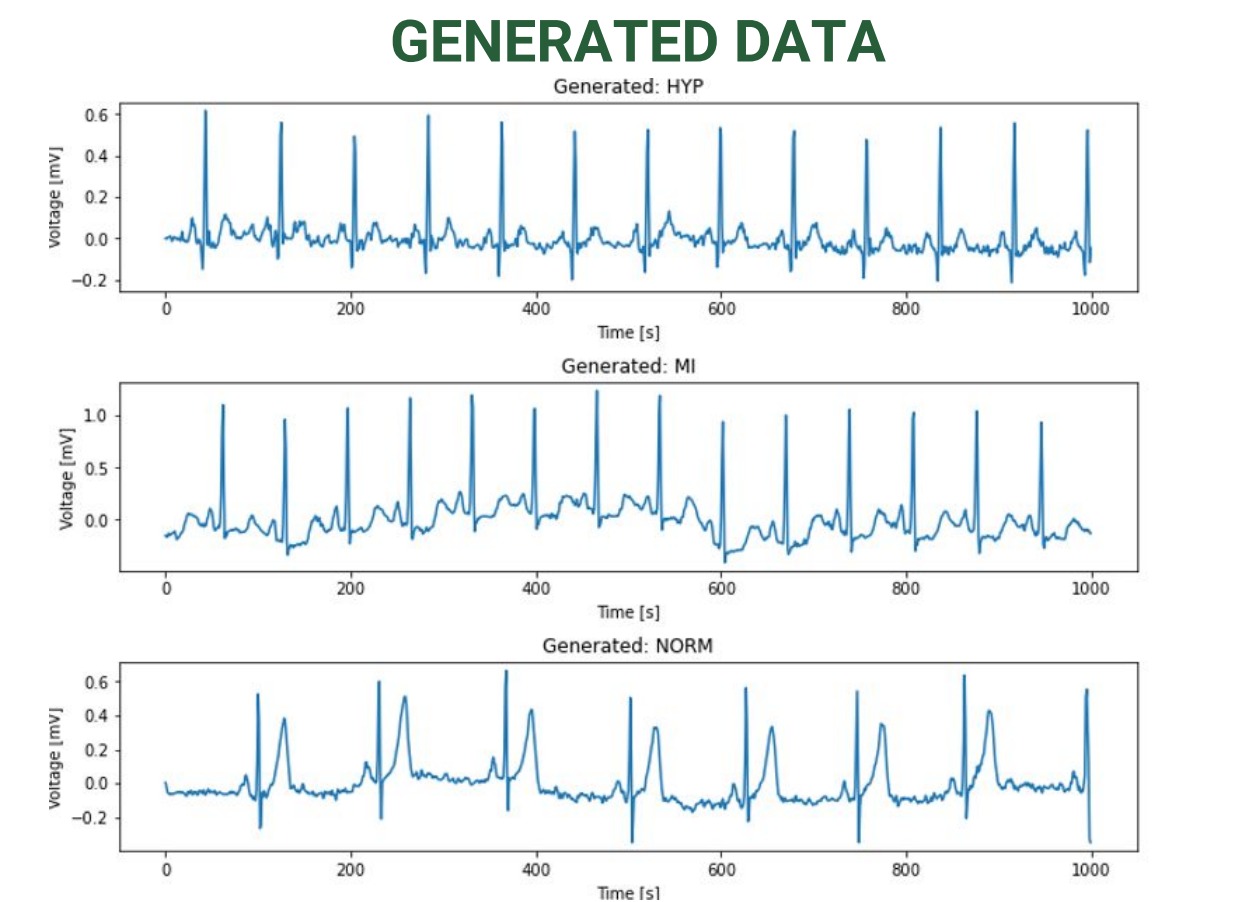
ECG Waveform Generation from Clinical Reports using State Space Diffusion Models | 2024-2025
Created a framework for generating physiologically realistic 12-lead ECG signals from clinical diagnostic text. Extracted diagnostic concepts from unstructured reports using rule-based and LLM-based methods, then mapped these to ECG parameters. Employed score-based diffusion with Structured State Space Models (SSSM) to generate primary leads, with remaining leads reconstructed via vectorcardiographic transformations. Validated through blinded clinical evaluation.
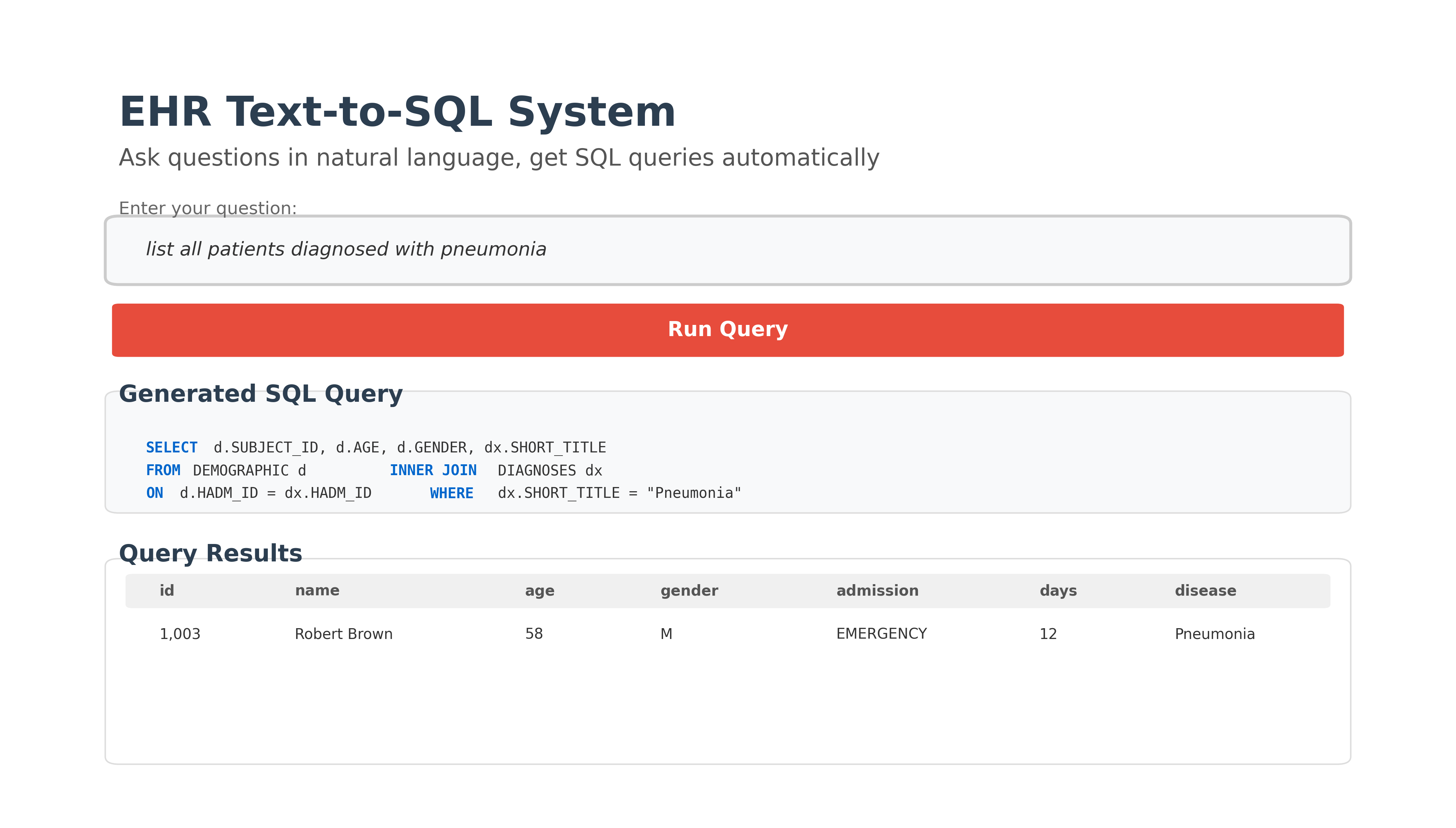
Text-to-SQL for Enhanced Electronic Health Records | 2024-2025
Developed a natural language interface for querying EHR databases, enabling clinicians without SQL expertise to retrieve patient information efficiently. Evaluated multiple state-of-the-art models including T5, BART, and PICARD on the MIMIC-IV dataset. PICARD achieved best performance through constrained decoding that enforces syntactic and schema consistency. Conducted comprehensive ablation studies and identified schema-awareness, pre-training, and constrained decoding as key components.
Time-Efficient Symmetric Key Encryption for ECG Waveforms | 2021-2022
Developed an encryption algorithm for securing ECG waveforms during transmission. Optimized matrix dimensions to minimize zero-padding when converting signals to square matrices, significantly reducing computational complexity for both encryption and decryption. The random key matrix uses double-precision values for security, while evaluation metrics validated preservation of diagnostic information throughout the encryption-decryption cycle.
Natural Language Processing
Dominant Narrative-Based News Summarization | 2024-2025
Explored transformer-based approaches for summarizing news articles while preserving their dominant narrative perspective. The challenge involves balancing multiple concerns: managing inherent bias in source material, compressing lengthy articles without losing key context, and maintaining coherence when narratives may be politically or socially contentious. Compared various BART model variants on articles about the Russia-Ukraine war and climate change. Our submission using DistilBART-CNN-12-6 achieved 4th place on the SemEval-2025 leaderboard with a BERTScore of 0.74203.
Subjectivity Detection in News Articles | 2024
Investigated automated detection of subjective language in news reporting, which is important for identifying potential bias and understanding how articles present information. Compared traditional machine learning methods (KNN, Random Forest, SVM) against recurrent neural networks (LSTM, GRU) and modern transformer architectures. Explored using part-of-speech tags as additional linguistic features, since certain grammatical patterns often signal subjective content. A RoBERTa model enhanced with POS features ranked 3rd at CLEF 2024 CheckThat! Lab with a macro-F1 score of 0.71.
Emotion Classification in Hinglish Code-Mixed Dialogue | 2023
Worked on recognizing emotions in Hinglish conversations, where speakers naturally blend Hindi and English within single sentences. Code-mixed text lacks the clear grammatical structure of single-language data, creating challenges for parsing, word disambiguation, and language identification. This is increasingly relevant as code-mixing is common in multilingual communities and social media. Evaluated specialized models trained on code-mixed data (HingBERT, Hing mBERT, HingRoBERTa) against traditional classifiers to understand which approaches handle the linguistic ambiguity most effectively.
Multimodal News Image Rematching with CLIP | 2023
Investigated the relationship between text and images in online news articles. Unlike image captioning where captions directly describe visible content, news images often have more complex semantic relationships with their accompanying text. The task becomes harder when articles use stock photos or AI-generated images rather than original photography. Applied the CLIP contrastive learning framework with DistilBERT for text encoding and ResNet50 for images, projecting both into a shared embedding space. Part of a benchmarking task for MediaEval 2023.
Fine-Grained Tamil Fake News Dataset with Expert Annotations and LLMs | 2024
Developed a fine-grained classification framework for detecting fake news in Tamil, a Dravidian language. Traditional binary classification overlooks the nuanced nature of misinformation. Created four distinct categories-Humor, Biased, Misleading, and Clickbait-through expert annotation of existing datasets. Addressed severe class imbalance using GPT-4o to generate synthetic Tamil sentences for underrepresented categories. Validated synthetic data quality through quantitative linguistic metrics (Type-Token Ratio, n-gram overlap, Shannon entropy) and human annotation achieving Cohen's Kappa of 0.75. Evaluated multiple classifier architectures on the augmented datasets including multilingual models (XLM-RoBERTa, mBERT, mDeBERTa), Indic language-specific models (Tamil-BERT, Indic-BERT, MuRIL), and language-agnostic models (LaBSE, LEALLA).